Server monitoring is important for optimum server performance to ensure no disruptions to your business. It involves keeping an eye on various metrics to ensure smooth operations and to easily pinpoint bottlenecks.
Server monitoring tools can help with this by monitoring the applications or the entire infrastructure. These tools can monitor the responsiveness of the server, its capacity, user load, and speed. They can also help with capacity planning by understanding the server's system resource usage.
Some examples of server monitoring tools include Datadog, SolarWinds, and Stackify's Retrace.
| Characteristics | Values |
|---|---|
| CPU Usage | Monitor the CPU usage of the server to ensure applications' performance |
| Memory Consumption | Monitor memory resources to ensure applications' performance |
| Disk Usage | Monitor disk activity to identify performance bottlenecks |
| Network Activity | Monitor network activity to identify hardware failure or overloading |
| Process Monitoring | Monitor all processes to ensure smooth server performance |
| Server Availability | Monitor server uptime to detect system failures |
| Server Health | Monitor server health to identify performance issues |
| Server Capacity | Monitor server capacity to plan for upgrades and growth |
| Application Performance | Monitor applications to ensure they meet performance objectives |
| Real-Time Alerts | Set up automatic alerts to identify potential issues |
| Historical Data | Collect historical data to identify security issues and attempted intrusions |
| Custom Dashboards | Create custom dashboards for a holistic view of server performance |
What You'll Learn
- General Host and Server Monitoring: CPU, Memory, Disk, Network and Process utilization
- Database Monitoring: Database Instance Activity, Query behaviour, and User Activity
- Application Performance Metrics: Requests per second, average response time, etc
- User Experience Metrics: Server-side processing time, error rates, latency, etc
- Server Capacity Metrics: Requests per second, data in, data out, etc
![]()
General Host and Server Monitoring: CPU, Memory, Disk, Network and Process utilization
General host and server monitoring involves tracking key performance indicators (KPIs) such as CPU, Memory, Disk, Network and Process Utilization. This provides insights into the overall health and performance of servers and helps identify potential bottlenecks or issues. Here are some details and instructions for monitoring these aspects:
CPU Utilization
CPU utilization measures the percentage of time the processor is busy executing tasks. High CPU utilization, such as consistently above 90%, indicates potential performance issues or bottlenecks. To avoid this, it is recommended to monitor CPU usage regularly and take necessary actions, such as optimizing software or adding more memory. Tools like OpManager and SolarWinds Server & Application Monitor (SAM) can help monitor CPU usage and identify performance bottlenecks.
Memory Utilization
Memory utilization refers to the amount of available memory on the system. It is essential to ensure that there is enough free memory, usually around 10%, to prevent performance issues. Monitoring memory usage helps identify memory leaks or inefficient memory allocation. Tools like OpManager and SAM provide detailed insights into memory utilization and can help identify potential issues.
Disk Utilization
Disk utilization involves monitoring the activity and performance of physical disks or storage devices. This includes tracking metrics such as disk queue length, disk idle time, disk read and write operations, and disk space usage. High disk queue lengths or low disk idle time can indicate potential bottlenecks. Tools like OpManager, LibreNMS, and SAM offer features to monitor disk performance and identify issues.
Network Utilization
Network utilization refers to monitoring network performance and usage. This includes metrics such as network bandwidth, network latency, data transfer rates, and network interface activity. Monitoring network utilization helps identify network bottlenecks, security issues, or abnormal access attempts. Tools like Datadog, Paessler PRTG Network Monitor, and SAM provide comprehensive network monitoring capabilities.
Process Utilization
Process utilization involves monitoring the performance and resource usage of individual processes running on the server. This includes tracking CPU and memory usage per process, identifying potential memory leaks, and analyzing process-wise resource utilization. Tools like OpManager and SAM offer process monitoring features to help identify processes that may be causing performance issues.
By regularly monitoring these key aspects of general host and server performance, administrators can ensure optimal server health, identify potential issues early on, and take necessary actions to optimize performance and resolve bottlenecks.
Hooking Up Five Monitors: The Ultimate Guide
You may want to see also
![]()
Database Monitoring: Database Instance Activity, Query behaviour, and User Activity
Database monitoring is a crucial aspect of server performance optimisation and involves tracking database instance activity, query behaviour, and user activity. Here are some detailed methods and tools to help you monitor these aspects effectively:
Database Instance Activity
Database instance activity monitoring provides insights into the performance of your database instances, helping you identify potential bottlenecks and optimise resource allocation. One way to achieve this is by using the Activity Monitor in SQL Server Management Studio (SSMS). The Activity Monitor runs queries on the monitored instance to gather information for its display panes. It is recommended to set the refresh interval to more than 10 seconds to avoid affecting server performance. To gain visibility into the actual activity, ensure you have the necessary permissions, such as VIEW SERVER STATE.
Query Behaviour
Query monitoring helps identify poorly performing queries, themes, or plugins that may be contributing to slow site speeds. Query Monitor, a WordPress plugin, provides valuable insights in this regard. It displays the page generation time, total time taken by SQL queries, and the total number of SQL queries. The Queries by Component panel is particularly useful as it aggregates information about database queries executed by each plugin and theme, helping pinpoint any underperforming elements. Additionally, the HTTP API Calls panel reveals "invisible" causes of slow sites, such as server-side HTTP requests.
User Activity
Monitoring user activity is crucial for identifying suspicious behaviour and preventing security breaches. Native Active Directory auditing tools can be used, but they are often time-consuming and complex. Lepide Auditor is a recommended alternative as it simplifies the process of detecting and reacting to insider threats. It offers Logon/Logoff Reporting and Permissions Modification Reports, making it easier to track logon activity and identify suspicious patterns. To set up user activity monitoring, follow these steps:
- Select Server Manager on the Windows server.
- Open the Group Policy Management console under the Manage tab.
- Navigate to Forest, Domain, Your Domain, and Domain Controllers.
- Create or edit a group policy object.
- In the Group Policy Editor, go to Computer Configuration > Policies > Windows Settings > Security Settings > Local Policies > Audit Policy.
- Enable Success and Failure auditing for relevant policies, such as Audit logon events.
- Return to Computer Configuration and enable Success and Failure auditing for Audit Logon, Audit Logoff, and Audit Special Logon.
- Secure Filtering, add users whose logons need tracking, or select "All users" to audit every domain user.
By effectively monitoring database instance activity, query behaviour, and user activity, you can ensure optimal server performance, identify potential issues, and maintain the security of your systems.
Monitoring Gas and Electricity Usage: Smart Meter Revolution
You may want to see also
![]()
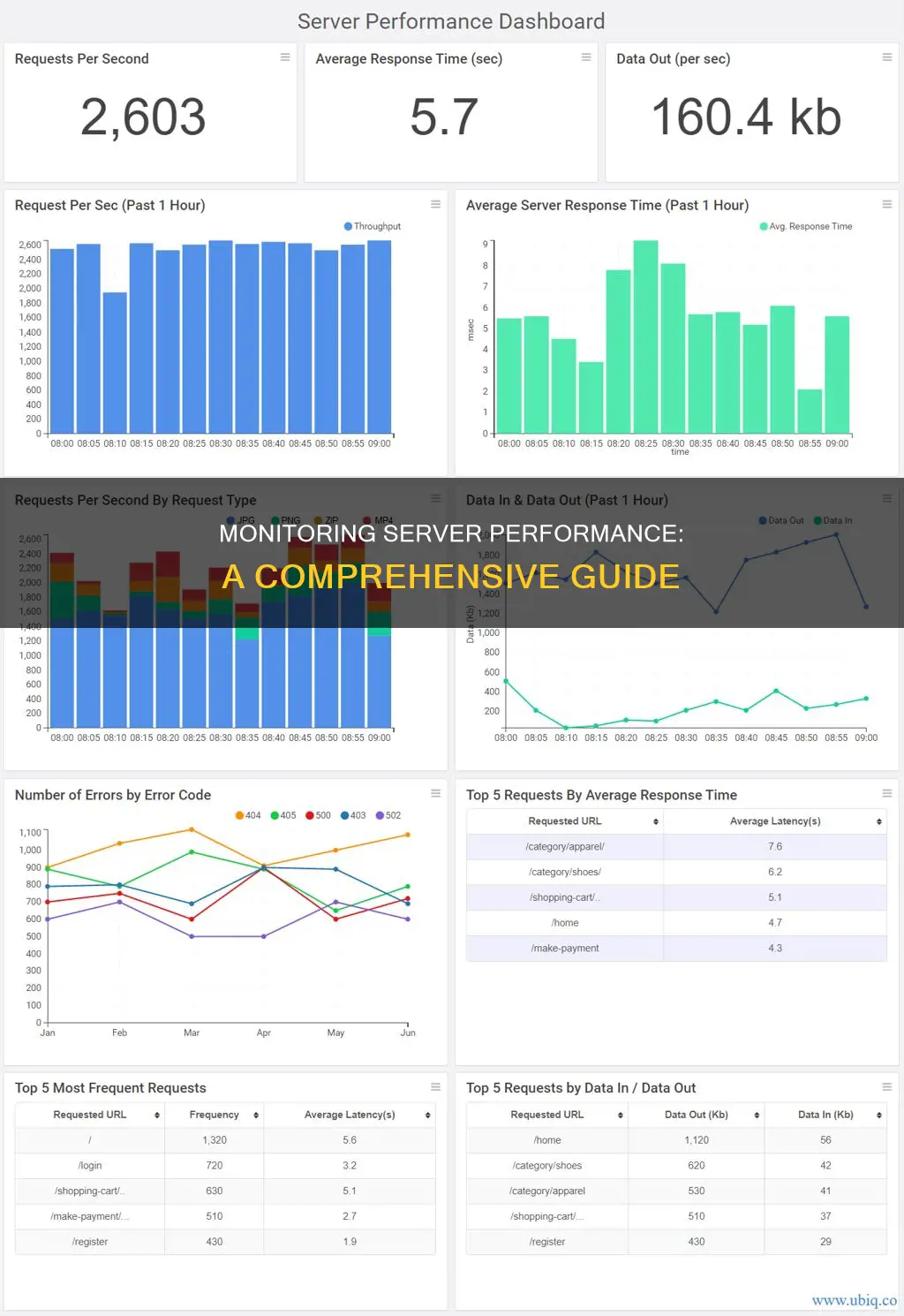
Application Performance Metrics: Requests per second, average response time, etc
Application performance metrics are a quantitative measure of how effectively an organisation achieves its business objectives. They are important for deciphering how an application supports a business and for revealing areas where improvements can be made.
Requests per second
Requests per second (also called throughput) is the number of requests your server receives every second. Large-scale applications can reach up to about 2,000 requests per second. This metric is a fundamental measure of the main purpose of a web server, which is to receive and process requests.
Average response time
The average response time (ART) is the average time the server takes to respond to all requests. This is a strong indicator of the overall performance of the application. In general, the lower this number is, the better. However, studies show that the ceiling for a user to have a sense of "seamlessness" while navigating through an application is around one second.
Peak response time
Similar to the average response time, the peak response time (PRT) is the measurement of the longest responses for all requests coming through the server. This is a good indicator of performance pain points in the application.
Hardware utilisation
Any application or server running is limited by the resources allocated to it. Therefore, keeping track of the utilisation of resources is key, primarily to determine if a resource bottleneck exists. There are three major aspects of a server to consider:
- CPU usage
- Memory usage
- Disk space and usage
Network bandwidth
Monitoring network bandwidth and related metrics is essential for maintaining high-performance server networks. This server performance metric measures bandwidth utilisation, throughput, and potential bottlenecks. This helps administrators take proactive measures to optimise network performance, ensure smooth data transmission, and deliver an efficient user experience.
Attaching Speakers to the Asus VC279 Monitor: A Guide
You may want to see also
![]()
User Experience Metrics: Server-side processing time, error rates, latency, etc
User experience metrics are crucial for understanding the performance of a server from the user's perspective. Here are some key user experience metrics to monitor:
- Server-side processing time: This refers to the time it takes for the server to process a request and send a response back to the user. It includes the time taken for data retrieval, formatting responses, and accessing databases. Optimising server-side processing time can lead to quicker loading times and an improved user experience.
- Error rates: Monitoring error rates helps identify issues with the server's performance or stability. High error rates can indicate problems with the server's hardware, software, or network connectivity. By tracking error rates, administrators can proactively identify and resolve issues before they cause significant disruptions.
- Latency: Latency refers to the time it takes for data to travel between two points on a network, such as between a user's device and a server. High latency can negatively impact the user experience, leading to slow website load times and poor performance. It is important to minimise latency by using techniques such as content delivery networks (CDNs) and optimising web page assets.
- Throughput: This measures the average amount of data transferred over a network in a given period. Monitoring throughput can help identify bottlenecks or performance issues in the server's ability to handle incoming and outgoing data.
- Bandwidth utilisation: Bandwidth refers to the maximum capacity of a network connection for data transfer. Monitoring bandwidth utilisation helps ensure that the server has sufficient bandwidth to handle expected traffic volumes. Insufficient bandwidth can lead to slow speeds and decreased performance.
- Uptime and downtime: Uptime refers to the percentage of time that a server is operational and available, while downtime refers to periods when the server is unavailable or experiences disruptions. Monitoring uptime and downtime helps track the reliability and stability of the server.
- Real user monitoring (RUM): This involves collecting performance data from actual user interactions with the server. RUM provides insights into how users experience the server's performance, including page load times, rendering speeds, and error rates.
By closely monitoring these user experience metrics, administrators can optimise server performance, identify potential issues, and ensure a smooth and reliable experience for end-users.
Ways to Measure Your Monitor's Width
You may want to see also
![]()
Server Capacity Metrics: Requests per second, data in, data out, etc
Server capacity metrics are crucial to understanding the performance of your server and application. They can help identify the root cause of hardware and software issues and prevent them in the future.
Requests per second
Also known as throughput, this is the number of requests handled by your server during a specific period. This provides a good indication of how busy your server is. If the number of requests per second is high, and your server does not have enough capacity, it will lead to a server crash.
Data in
This is the request payload size received by the server. A lower rate is better, as it means smaller payloads are being sent to the server. A high data input can indicate that the application is requesting more information than it needs.
Data out
This is the size of the response payload sent back to users from the server. Larger payloads here will increase load times for the application. They may also put a strain on your server's network infrastructure, as well as that of your users. Keeping track of your data out will help keep your responses light and ensure faster load times for the application.
Monitor Size: Performance Impact and Visual Experience
You may want to see also
Frequently asked questions
Some good server monitoring tools include SolarWinds, ManageEngine OpManager, Stackify Retrace, LibreNMS, and Atera.
Some key performance areas to monitor are the server's physical status, CPU and memory, uptime, disk activity, page file usage, context switching, time synchronization, handle usage, process activities, network activity, and OS logs.
Some best practices for server performance monitoring include establishing a clear baseline, being consistent in performance monitoring, leveraging monitoring tools, setting up detailed alerts, and tracking relevant metrics.







