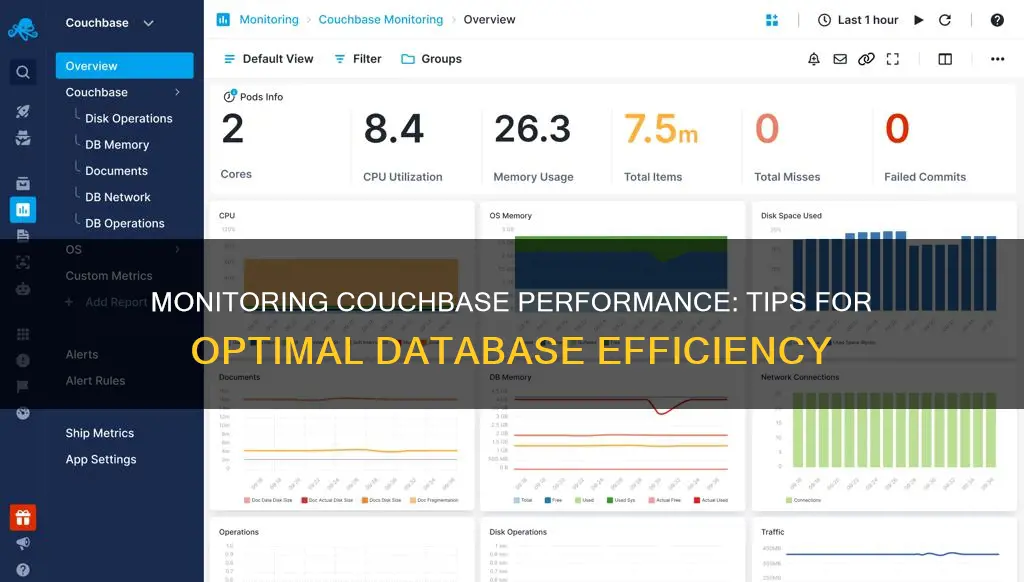
Monitoring Couchbase performance is a critical element for a successful deployment of any mission-critical system. Couchbase is a distributed, high-performance, cache and NoSQL database in a single cluster architecture. It is designed to provide scalable document access with low latency and is optimized for interactive applications. Couchbase monitoring tools provide detailed insights into database activity and health, including performance, availability, and usage statistics. This enables users to actively monitor all aspects of the Couchbase server, such as health, availability, and response time, to ensure sustained throughput.
| Characteristics | Values |
|---|---|
| Performance metrics | CPU, connectivity, retransmissions, requests, request time, RAM usage, swap usage, current items, hard disk space, memory |
| Monitoring | Dynatrace, Couchbase cluster overview pages, Site24x7 plugin, Couchbase administration console, command line utilities, REST interface, Applications Manager |
| Alerts | Visual, email |
What You'll Learn
![]()
Monitoring Couchbase cluster health and performance
To effectively monitor Couchbase, it's essential to consider two perspectives: the cluster as a whole and its individual nodes or servers. By monitoring resource consumption and available compute capacity per node, administrators can ensure optimal performance. This includes tracking CPU usage, memory usage, node disk usage, and swap memory usage. Additionally, monitoring the health of data buckets is vital, as it provides insights into the application's health and allows for informed decision-making.
Couchbase provides cluster metrics, activity logs, and alerts to notify administrators of critical cluster health events. These metrics help monitor current and past cluster performance, allowing administrators to track specific metrics over specified time frames or in near-real-time. The Activity Logs in Capella offer a comprehensive timeline of events, including summaries, severity, resources affected, actors, and timestamps.
Couchbase also offers health check services, providing basic and comprehensive reports on the overall health of a Couchbase cluster. These reports identify issues causing poor health and offer recommendations for improvement. Health checks are beneficial for performance tuning, capacity planning, and reducing TCO. They help identify and analyse root causes of high resource utilization and poor end-user experience.
By leveraging tools like the Couchbase Web Console, CLI, and REST API, administrators can efficiently monitor Couchbase Server statistics, ensuring sustained throughput and optimal performance.
Studio Monitors: Why You Need Them
You may want to see also
![]()
Viewing detailed database activity
To view detailed activity logs in Couchbase, you need a project role in any project where you want to see events generated from its clusters. You can then open the relevant organisation, project, or cluster, click the Settings tab, and select Activity Log from the navigation menu.
Each event in the Activity Log includes details such as the title of the event, its severity level (Info, Warning, or Critical), the Capella resource where it occurred, who initiated it, and the date and time.
You can filter Activity Logs by time range, user, cluster, project, event severity, event tag, and time range. Multiple filters can be combined to narrow down the results.
For a more in-depth view of Couchbase activity, you can leverage the Couchbase REST API (http://:8091/pools/default). This provides insights into compute resources consumed per node, node state, system statistics, and Couchbase-specific statistics.
Node State (clusterMembership) allows you to monitor for 'active' nodes to ensure they are participating in the cluster. Critical events are indicated by "inactiveFailed", which shows that a node has failed and requires administrator intervention.
System Statistics (systemStats) provides basic capacity consumption statistics for CPU (cpu_utilization), SWAP (swap_used), and free memory (mem_free).
Couchbase Specific (interestingStats) offers insights into resources consumed by individual nodes, including disk consumption (couch_docs_actual_disk_size), physical memory used (memory_used), and background fetches (ep_bg_fetched).
Additionally, you can use the REST API (http://:8091/pools/default/buckets/stats) to monitor the health of your buckets. This includes metrics such as Operations Per Second (ops), Cache Miss Rate (ep_cache_miss_rate), Fragmentation (couch_docs_fragmentation), and Working Set (ep_bg_fetched and vb_active_resident_items_ratio).
By monitoring these detailed database activities, you can gain valuable insights into the performance and health of your Couchbase clusters and take proactive measures to ensure optimal performance.
Monitoring Docker Container Performance: A Comprehensive Guide
You may want to see also
![]()
Tracking node status and failures
Node Status:
- Node State: Monitor the state of each node in the cluster using the nodeStatuses endpoint, which provides information on whether a node is "active" or "inactiveFailed." This allows you to guarantee that all nodes are participating in the cluster and take necessary actions in case of inactive or failed nodes.
- System Statistics: Keep track of basic capacity consumption statistics such as CPU utilisation, SWAP memory, and free memory for each node. Address any constraints on these resources and evaluate the need for additional nodes.
- Couchbase-specific Statistics: Gain further insight into the resources consumed by each node, including disk space consumed by Couchbase, physical memory used, and the number of background fetches.
Node Failures:
- Failover: Understand the two types of failover—graceful and hard. Graceful failover allows for the proactive removal of a node during system maintenance, while hard failover is reactive and used when a node becomes unavailable or unstable.
- Automatic Failover: Enable automatic failover in the Couchbase Web Console or through CLI and REST API commands. This allows Couchbase to automatically fail over dead or unhealthy nodes, ensuring continuity of cluster operations.
- Node Backup: Ensure the Couchbase Backup Service has consistent access to its archive location to prevent backup failures and reduce data durability.
- Node Health Checks: Regularly perform health checks on nodes to identify any issues. The Couchbase Cluster Manager periodically contacts all nodes and marks inactive nodes as unhealthy, triggering a failover if Auto-Failover is enabled.
- Node Replacement: In case of node failures or performance issues, consider replacing nodes with identical hardware to maintain predictable application performance.
- Corrective Actions: Stay informed about node failures and take necessary corrective actions. This may include adding more nodes to the cluster, increasing memory or disk space, or adjusting resource allocation.
Monitoring Linux Server Performance: Key Metrics and Methods
You may want to see also
![]()
Analysing data bucket operations
- Understanding Bucket Types: Couchbase offers different types of buckets, including Couchbase buckets, Ephemeral buckets, and Memcached buckets. Each type has unique characteristics and use cases. For instance, Couchbase buckets provide data persistence and replication, while Ephemeral buckets are ideal when persistence is not required. Understanding the specific attributes and behaviours of each bucket type is essential for effective monitoring.
- Monitoring Bucket Statistics: By leveraging the Couchbase REST API, you can gain valuable insights into the health and performance of your buckets. Key metrics to monitor include Operations Per Second (ops), which measures the total number of get, set, increment, and decrement operations; Cache Miss Rate (ep_cache_miss_rate), which indicates the ratio of requested objects found in the cache versus those fetched from disk; and Fragmentation (couch_docs_fragmentation), which is important to track to maintain a healthy database, especially when auto-compaction is enabled.
- Optimising Working Set: Understanding the working set of your Couchbase cluster is crucial. By analysing metrics such as ep_cache_miss_ratio, resident items ratio, and memory headroom, you can determine if your bucket has sufficient capacity to store frequently requested objects in memory. This analysis will help you forecast the need for additional nodes and expand memory capacity effectively.
- Monitoring Disk Drain: Keeping a close eye on the disk drain rate is vital, regardless of your application's nature. The ep_queue_size metric in the REST API provides insights into the number of changes pending in the queue. Monitoring both the queue fill (ep_diskqueue_fill) and the rate at which the queue is draining (ep_diskqueue_drain) will help you track trends over time and ensure optimal performance.
- Tracking Connection Requests: It is important to track the number of open and rejected connection requests to your Couchbase nodes. The curr_connections and rejected_conns statistics in the CBSTATS utility or the REST API can help you understand if any connection requests were rejected, which may indicate potential issues or capacity constraints.
- Monitoring Background Fetches: When an object is requested by an application and not found in the cache, Couchbase performs a background fetch from disk. The ep_bg_fetched metric measures the number of such fetches. While managing a 100% working set is ideal, a significant increase in background fetches may indicate a cluster under stress or a smaller working set.
- Ensuring Adequate I/O Resources: Monitoring the number of items queued for persistence is crucial to ensure your application has sufficient I/O resources. Couchbase's ability to provide data durability by persisting data to disk is a significant advantage. However, if the asynchronous persistence operation becomes overloaded, it could impact application performance. Therefore, closely monitoring ep_queue_size and ep_flusher_todo is essential, especially in heavy write systems.
- Managing Ejected Replica Values: Tracking the vb_num_eject_replicas statistic reveals the number of times Couchbase ejected replica values from memory due to a bucket reaching its low water mark. While this is a normal memory management process, consistently observing this behaviour or an increasing trend could indicate potential issues. It is also a way to prevent out-of-memory scenarios, which should be avoided in production clusters.
- Understanding Warmup Processes: Couchbase avoids stale cache scenarios by performing a 'warmup' process when a node starts up. Monitoring warmup processes provides insights into how quickly a node becomes available to handle read and write requests. The ep_warmup_value_count and ep_warmup_state metrics help track the progress and status of the warmup process, ensuring efficient cluster operations.
- Monitoring Memory Consumption: As Couchbase is both a NoSQL persistence engine and a cache, monitoring memory consumption is vital. The mem_used metric in the REST API or CBSTATS utility helps track the memory utilisation of the Couchbase server ep_engine, ensuring optimal performance and resource allocation.
By following these guidelines and analysing data bucket operations, you can make informed decisions, optimise your Couchbase cluster's performance, and ensure sustained throughput.
Easy Holter Monitor Gel Removal: Tips and Tricks
You may want to see also
![]()
Visualising performance with charts
Visualising Couchbase performance with charts is a straightforward process. Users with the Full Admin or Bucket Admin role can access the Dashboard of the Couchbase Web Console to view and create groups of charts. The Dashboard is the default landing page after logging in, and can also be accessed by left-clicking on the Dashboard tab in the left-hand navigation bar.
From the Dashboard, users can assemble charts interactively and monitor statistics for Couchbase Server and all services. To create a new chart, click on the drop-down list labelled "Choose Dashboard or create your own". From here, you can start with a blank canvas or use the current charts as a base. Once you have clicked Save, you will be prompted to create a new Group for your charts. After adding a group, click on "Add a Chart" and choose a size and data metric.
The Couchbase Web Console also allows you to customise the time frame, buckets, and individual nodes for your charts. Hovering your mouse pointer over a metric chart will display date, time, and resource information for that specific data point. You can also zoom in on a particular region of a chart by dragging your pointer over it, and the timeframe will automatically adjust to match your selection.
In addition to the Couchbase Web Console, other tools such as Dynatrace and Grafana can be used to visualise Couchbase performance with charts. Dynatrace auto-detects your Couchbase databases and provides cluster charts and node metrics, while Grafana allows you to build observability dashboards with Prometheus and Couchbase.
Plasma vs LCD: Which Monitor is Best for You?
You may want to see also
Frequently asked questions
Couchbase Server can be monitored through Couchbase Web Console, CLI, and the REST API.
At the cluster level, identify which buckets are consuming the most resources. At the application level, find out how many requests are not handled by upstream caching and are triggering Couchbase operations.
Monitoring Couchbase performance requires two different perspectives: the cluster as a whole and individual application buckets. It's also important to monitor resource consumption, available compute capacity per node, and disk capacity.







