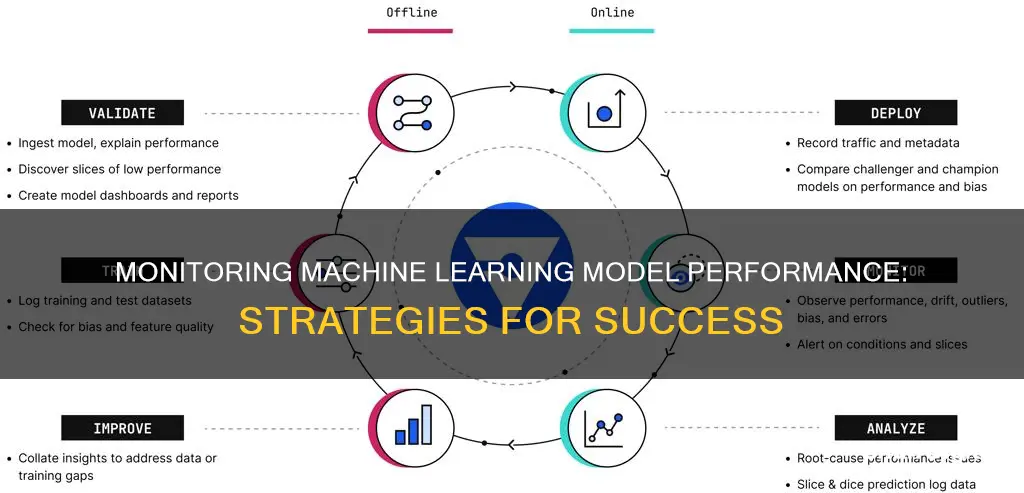
Machine learning model monitoring is a critical aspect of the machine learning lifecycle, ensuring optimal performance, accuracy, and reliability. It involves tracking various metrics and system characteristics to detect issues and improve the model's performance in real-time. Here are some key reasons why monitoring is essential:
- Performance Tracking: Monitoring helps identify deviations from expected performance levels, allowing data scientists to fine-tune the model and improve accuracy.
- Concept Drift: Real-world data can change over time, and monitoring helps detect when the distribution of incoming data no longer matches the training data, prompting retraining or updates.
- Data Quality Assurance: Monitoring ensures that the input data remains of high quality and consistent with training data, as inconsistent or noisy data can negatively impact model performance.
- Compliance and Fairness: Monitoring can reveal biases in model predictions, ensuring fairness and compliance with legal and ethical standards.
- User Experience and Business Impact: Monitoring enables organizations to track customer satisfaction and tie model performance to key business metrics, ensuring the ML system aligns with organizational goals.
What You'll Learn
![]()
Monitor data quality and integrity
Monitoring data quality and integrity is essential for maintaining the reliability and accuracy of machine learning models. Here are some key considerations and techniques for effective data monitoring:
- Input Data Quality: Inconsistent or noisy input data can negatively impact model performance. Monitoring helps ensure that the data fed into the model remains of high quality.
- Label Quality: In supervised learning, accurate labels are crucial. Monitoring can help identify issues with mislabeled data and guide corrective actions.
- Data Drift: Changes in the distribution of input data over time can lead to a decline in model performance, known as data drift. Monitoring helps identify when drift occurs and prompts retraining or model updates.
- Data Validation: Implement automated and manual quality checks at various stages of the data pipeline to identify outliers, anomalies, missing values, invalid data formats, duplicate records, or inconsistencies.
- Data Schema Validation: Ensure that the data conforms to a predefined schema or structure by validating incoming data against it.
- Data Profiling: Examine the data to understand its characteristics, properties, and relationships, enabling the identification of data quality issues.
- Data Cleansing: Correct inaccuracies, duplicate entries, and inconsistencies in the data to improve overall data quality.
- Data Pipeline Monitoring: Data pipelines can introduce errors and inconsistencies. Establish solid pipeline monitoring, error handling, and testing procedures to guarantee precise data processing and delivery to ML models.
- Data Versioning and Lineage Tracking: Use data versioning tools to track dataset modifications and maintain metadata for each version, providing a comprehensive view of data evolution. Implement lineage tracking solutions to follow data from its source through transformations, streamlining debugging and impact analysis.
- Data Governance and Cataloguing: Appoint data stewards to oversee data quality and adherence to data governance policies. Develop a centralized data catalog to record information about data sources, attributes, and metadata. Implement role-based access controls and well-defined data governance policies.
- Data Privacy and Security: Employ data anonymization, encryption, and access control measures to protect data from unauthorized access and misuse. Perform regular audits to ensure compliance with data privacy and security regulations.
- Real-time Monitoring: Implement real-time monitoring to detect issues promptly, especially in applications where timely predictions are critical, such as fraud detection or recommendation systems.
- Alerting and Notification Systems: Set up alerting systems to notify stakeholders when the model's performance deviates from expected standards. Define thresholds for key metrics and establish protocols for addressing issues.
Resetting Your ASUS VG245 Monitor: A Step-by-Step Guide
You may want to see also
![]()
Track data and target drift
Tracking data and target drift is essential to maintaining the accuracy and reliability of machine learning models over time. Data drift occurs when there are changes in the distribution of the input data that the model receives during production, which can lead to a decline in model performance. Target drift, also known as concept drift, occurs when the relationship between the input data and the desired output changes, resulting in the model's inability to make accurate predictions.
To effectively track data and target drift, several strategies can be employed:
- Monitor input data distribution: Compare the distribution of the incoming data with previous batches or the training data to detect significant shifts. This can be done using statistical methods, such as the Kolmogorov-Smirnov (K-S) test, Population Stability Index (PSI), or distance metrics like the Wasserstein Distance.
- Evaluate model performance: Regularly assess the model's performance using appropriate metrics such as accuracy, precision, recall, and F1-score. Deviations from expected performance levels indicate potential data or target drift.
- Detect concept drift: Monitor changes in the relationship between input features and the target variable. This can be achieved through techniques like statistical tests, hypothesis testing, or classifier-based approaches.
- Set up alerting systems: Define thresholds for key metrics and establish protocols for addressing issues. Notify relevant stakeholders when the model's performance deviates from the expected standards.
- Monitor data quality: Regularly assess the quality of input data to ensure it remains accurate and relevant. Detect and handle anomalies, outliers, and missing values that may impact model performance.
- Implement automated retraining: Establish pipelines to periodically update models with fresh data, helping them adapt to evolving patterns and maintain accuracy.
- Monitor for biases: Continuously evaluate model predictions for any signs of bias or fairness issues, especially in applications with potential ethical implications.
By following these strategies, machine learning practitioners can effectively track data and target drift, ensuring that their models remain reliable and accurate even in dynamic environments.
Connecting Your Surface: Easy Monitor Setup Guide
You may want to see also
![]()
Measure model performance
The most direct way to know if your model is performing well is to compare your predictions with the actual values. You can use the same metrics from the model training phase, such as Precision/Recall for classification and RMSE for regression. If something is wrong with the data quality or real-world patterns, you will see the metrics creep down.
There are a few things to keep in mind:
- The ground truth or actual labels often come with a delay, especially for long-horizon forecasts or when there is a lag in data delivery. In some cases, you may need to make an extra effort to label new data to check if your predictions are correct. In such cases, it makes sense to first track data and target drift as an early warning.
- You need to track not just the model quality but also the relevant business KPIs. For example, a decrease in the ROC AUC may not directly impact marketing conversions, so it is vital to connect model quality to business metrics or find interpretable proxies.
- Your quality metrics should fit the use case. For instance, the accuracy metric is far from ideal if you have unbalanced classes. With regression problems, you might care about the error sign, so you should track not just the absolute values but also the error distribution.
Your goal is to track how well the model serves its purpose and how to debug it when things go wrong.
Performance by Segment
For many models, the basic monitoring setup described above will be sufficient. But for more critical use cases, you may need to monitor additional items. For example, you may want to know where the model makes more mistakes and where it works best.
You might already know some specific segments to track, such as model accuracy for premium customers versus the overall base. This would require a custom quality metric calculated only for the objects inside the segment you define.
In other cases, it would make sense to proactively search for segments of low performance. For example, if your real estate pricing model consistently suggests higher-than-actual quotes in a particular geographic area, that is something you want to notice!
Depending on the use case, you can tackle this by adding post-processing or business logic on top of the model output, or by rebuilding the model to account for the low-performing segment.
Your goal is to go beyond aggregate performance and understand the model quality on specific slices of data.
Fairness and Compliance
When it comes to finance, healthcare, education, and other areas where model decisions can have serious implications, you need to scrutinize your models even more.
For example, the model performance may vary for different demographic groups based on their representation in the training data. Model creators need to be aware of this impact and have tools to mitigate unfairness, along with regulators and stakeholders.
For that, you need to track suitable metrics such as parity in the accuracy rate. It applies to both model validation and ongoing production monitoring. So, a few more metrics for your dashboard!
Your goal is to ensure fair treatment for all sub-groups and track compliance.
Connecting X10 Cameras: Monitor Setup Guide
You may want to see also
![]()
Monitor performance by segment
Tracking performance by segment is a crucial aspect of monitoring machine learning models. It enables a deep understanding of the model's quality on specific slices of data, helping to identify critical areas such as where the model makes mistakes and where it performs the best.
- Define segments to monitor: You might already have specific segments in mind, such as monitoring model accuracy for premium customers versus overall consumers. This requires defining a custom quality metric calculated only for the objects within the defined segment.
- Identify low-performance segments: Be vigilant for segments where the model consistently underperforms or provides inaccurate results. For example, if you are working on a vehicle pricing model and it constantly suggests higher-than-actual quotes in a specific region, this is a low-performance segment that needs improvement.
- Utilize appropriate tools: There are various tools available to help monitor performance by segment, such as Valohai, which offers infrastructure to collect, version, and visualize metrics. Another tool is Fairlearn, which helps to ensure fair treatment for all sub-groups and track compliance.
- Monitor for biases: Monitoring bias is crucial, especially in critical areas like healthcare and finance, where model decisions can have serious implications. As a model creator, be aware of performance variations in different circumstances, such as demographic groups with varying representation in the training data.
- Fine-tune marketing strategies: Machine learning algorithms for customer segmentation can help fine-tune product marketing strategies. For example, you can run ad campaigns targeted at random samples from various segments and then adjust your strategy based on the most active groups.
- Consider the target audience: Before applying machine learning segmentation, define your target audience and the elements that will be important to them. For example, if your focus is on specific locations, filter your data accordingly, as geographic location will be irrelevant in this case.
By effectively monitoring performance by segment, you can gain valuable insights into the model's performance on specific slices of data and make informed decisions to improve the model's overall performance.
Folding Your ASUS Monitor Stand: A Step-by-Step Guide
You may want to see also
![]()
Ensure compliance and fairness
Ensuring compliance and fairness in machine learning models is essential to prevent discrimination and unfair treatment of individuals or groups. Here are some strategies to achieve this:
- Monitor for biases: Use tools to detect and mitigate biases in the model predictions, especially those with potential ethical implications. Address biases such as language bias, gender bias, and political bias.
- Fairness criteria and metrics: Define fairness criteria and metrics to evaluate the model's performance regarding fairness. Examples include independence, separation, sufficiency, demographic parity, equalized odds, and individual fairness.
- Address sensitive attributes: Handle sensitive attributes like gender, race, or age carefully. Ensure these attributes do not lead to discriminatory outcomes or unfair treatment.
- Regulatory compliance: In regulated industries, ensure the model complies with legal and ethical standards to maintain transparency and accountability.
- User feedback: Consider user feedback loops to improve the model's performance and address any fairness concerns.
- Continuous improvement: Continuously improve the model by incorporating feedback from deployed ML models into the model-building phase.
- Data preprocessing: Remove or mitigate biases in the training data through data preprocessing techniques such as re-sampling, re-labelling, or adversarial techniques.
- Model optimization: Add constraints to the model optimization process to improve fairness, such as equal false positive rates or true positive rates across different groups.
- Post-processing: Modify the model's output through techniques like thresholding or re-weighting schemes to ensure fairness.
Removing Subscriptions from Replication Monitor: A Step-by-Step Guide
You may want to see also
Frequently asked questions
Machine Learning Model Monitoring involves measuring and tracking the performance of a machine learning model during its training and real-time deployment. This includes defining performance measures such as accuracy, F1 score, and recall, and comparing the model's predictions with known values.
ML Model Monitoring is critical to improving and maintaining the performance of machine learning models. It provides insights into model behaviour, detects issues such as concept drift and data drift, and helps identify the root causes of problems. Additionally, it ensures compliance with legal and ethical standards and enhances user experience by meeting expectations.
ML Model Monitoring can be divided into functional monitoring and operational monitoring. Functional monitoring focuses on assessing the model's predictive accuracy and its ability to adapt to changing data. It involves tracking metrics such as accuracy, precision, recall, and F1 score. On the other hand, operational monitoring deals with the model's interactions with the production environment, including resource utilization, response time, error rates, and throughput.
Monitoring data quality is crucial for the performance of ML models. This includes ensuring the input data remains of high quality and addressing issues such as inconsistent or noisy data. Additionally, in supervised learning, the quality of labels is essential, and monitoring can help identify mislabeled data.
There are several techniques for monitoring ML models, including tracking performance metrics, monitoring data distribution, comparing against a benchmark model, and monitoring concept drift. It's important to select metrics that align with business objectives and provide a comprehensive view of the model's performance.