Elasticsearch is a search engine based on the Lucene library that offers log analytics, real-time application monitoring, and click stream analytics. It is a highly scalable, distributed, open-source RESTful search and analytics engine. It stores and retrieves data structures in real-time and has multi-tenant capabilities with an HTTP web interface. To monitor Elasticsearch performance, it is important to use tools that give deep visibility into the Elasticsearch environment and turn data into actionable insights. This includes monitoring key performance metrics like disk I/O, CPU usage, memory usage, and node health for each node.
| Characteristics | Values |
|---|---|
| Cluster health | Disk I/O, CPU usage, memory usage, node health, JVM metrics |
| Node availability | Real-time health of each node |
| Index performance | Indexing rate, refresh time, merge time, query latency, request rate, file system cache usage |
| Search performance | Query latency, request rate, filter cache |
| Thread pool monitoring | Search, index, merge, bulk |
| Log management | Loggly, Kibana |
| Data sources | Prometheus, Grafana |
| Tools | Cerebro, Kopf, ElasticHQ, Kibana, Beats, Stackify |
| Data disks | /data1, /data2, /data3, /data4 |
| REST APIs | Cluster health, cluster stats, node stats |
| HTTP monitoring | Cluster health, response times, HTTP status, JVM heap used percentage |
| Java logs | /var/log/elasticsearch/* |
| HTTP access logs | Nginx as a reverse proxy |
| Performance | Requests by user satisfaction, requests per minute, HTTP error rate, user satisfaction score |
What You'll Learn
![]()
Monitor cluster health and node availability
Monitoring cluster health and node availability is crucial to maintaining optimal performance in your Elasticsearch environment. Here are some detailed instructions and insights to help you achieve that:
Monitor Cluster Health:
The health of your Elasticsearch cluster directly impacts its performance. You can use various tools and methods to monitor and improve cluster health:
- Elasticsearch APIs: Elasticsearch provides a rich set of APIs to monitor cluster health, such as the Cluster Health API, which returns the health status of the cluster and its data streams/indices. You can also use tools like curl to check the cluster health by making a request to 'http://localhost:9200/_cluster/health'.
- Kibana: Kibana offers a user-friendly interface to monitor your Elasticsearch cluster. Click "Overview" in the Elasticsearch section to view key metrics and indicators of the overall health of your cluster. Kibana highlights issues that require attention in yellow or red. You can also set up watches to alert you when the cluster status changes.
- Elasticsearch cat data: Elasticsearch's `_cat/shards` endpoint provides valuable information about what's happening inside your cluster. It offers nearly 60 data values for each shard, including "indexing.index_total" and "indexing.index_time," which can help identify indexing hotspots and monitor the rate of change in your cluster.
- Monitoring Tools: Utilize monitoring tools like SolarWinds Observability, Loggly, and ManageEngine Applications Manager for comprehensive insights into your Elasticsearch cluster's health and performance. These tools help collect and analyze data, providing visibility into potential issues.
Monitor Node Availability:
Node availability and performance are critical to the overall health of your Elasticsearch cluster:
- Monitor Key Performance Metrics: Keep a close eye on metrics such as disk I/O, CPU usage, memory usage, and node health for each Elasticsearch node in real time. JVM metrics are particularly important when CPU spikes occur, as Elasticsearch runs inside the Java Virtual Machine.
- Java Virtual Machine (JVM) Monitoring: As Elasticsearch operates within the JVM, monitoring JVM memory and garbage collection statistics is essential for understanding Elasticsearch memory usage. High garbage collection activity may indicate potential issues with memory allocation or a stressed thread pool.
- Thread Pool Monitoring: Elasticsearch nodes use thread pools to manage thread memory and CPU consumption. Monitor thread pools like search, index, merge, and bulk to avoid thread pool issues caused by pending requests, slow nodes, or thread pool rejections.
Easy Speaker Setup: Element Monitor and Desktop Edition
You may want to see also
![]()
Observe index performance
Observing index performance is crucial for maintaining optimal Elasticsearch operations. Here are some detailed instructions and considerations for monitoring and optimising index performance:
Understanding Index Performance Metrics
The performance of an Elasticsearch index is influenced by various factors, including the machine it's installed on and the workload it handles. Here are some key metrics to monitor:
- Disk I/O and CPU Usage: Keep a close eye on the disk input/output operations and CPU utilisation for all nodes in your Elasticsearch cluster. High resource usage may indicate potential bottlenecks or performance issues.
- Memory Usage: Monitor the memory consumption of each node, especially when CPU spikes occur. This is important as Elasticsearch runs inside the Java Virtual Machine (JVM), and high memory usage can impact performance.
- Node Health: Real-time node health monitoring is essential. Ensure you have insights into the health status of each Elasticsearch node to promptly identify and address any issues.
- Indexing Rate: Calculate the indexing rate by running indexing benchmarks with a fixed number of records. Monitor for sudden spikes or dips in this rate, as they could indicate data source problems or the need to adjust refresh and merge times.
- Query Latency and Request Rate: Track query latency and request rates to understand the system's usage and performance. High latency can impact users directly, so it's crucial to receive alerts for anomalies in this metric.
Optimisation Techniques for Index Performance
- Bulk Requests: Using bulk requests, where you index multiple documents at once, can significantly improve performance compared to single-document index requests. Experiment with different batch sizes to find the optimal number of documents per request for your data.
- Multiple Workers/Threads: Utilise multiple workers or threads to send data to Elasticsearch. This helps maximise the utilisation of your cluster's resources and can also reduce the cost of each fsync operation.
- Refresh Interval: The default refresh interval in Elasticsearch is 1 second, but you can adjust it based on your search traffic. If you have minimal search traffic, increasing the refresh interval can optimise indexing speed.
- Disable Replicas for Initial Loads: If you're loading a large amount of data into Elasticsearch, consider disabling replicas (index.number_of_replicas=0) temporarily. This speeds up indexing, but be aware that data loss may occur if a node fails during this process.
- Use Faster Hardware: Consider upgrading to faster hardware, such as SSD drives, if your indexing or search operations are I/O-bound. SSDs tend to outperform spinning disks due to the mix of random and sequential reads involved in Elasticsearch operations.
- Local vs. Remote Storage: Directly attached (local) storage often performs better than remote storage due to simpler configurations and reduced communication overheads. However, carefully tuned remote storage can also achieve acceptable performance.
- Indexing Buffer Size: Ensure the indexing buffer size is sufficient for heavy indexing operations. The default setting of 10% is usually enough, but for nodes with multiple shards performing heavy indexing, you may need to increase it.
- Cross-Cluster Replication: To prevent searching from competing with indexing for resources, consider setting up two clusters and using cross-cluster replication. Route all searches to the cluster with follower indices to free up resources for indexing on the leader indices.
- Avoid Hot Spotting: Ensure even distribution of node resources, shards, and requests to prevent hot spotting. Hot spotting can degrade overall cluster performance by causing continual node synchronisation issues.
Ultra-Wide Monitor Size Guide: Matching 24-Inch Heights
You may want to see also
![]()
Track search performance
Tracking search performance is an important aspect of monitoring Elasticsearch. Here are some key considerations and steps to effectively track and optimize search performance in your Elasticsearch environment:
Query Latency and Request Rate:
Query latency is a critical metric that directly impacts user experience. It's essential to set up alerts for anomalies in query latency. By tracking the request rate alongside query latency, you can gain an overview of system utilization. High query latency and a high request rate may indicate performance issues that need to be addressed.
Filter Cache:
Elasticsearch caches filters by default. When executing a query with a filter, Elasticsearch finds matching documents and builds a structure called a bitset. If the same filter is used in subsequent queries, the information in the bitset is reused, saving I/O operations and CPU cycles and improving query execution speed.
Kibana Monitoring:
Kibana offers a comprehensive collection of dashboards and tools to monitor and optimize the Elastic Stack, including Elasticsearch. Kibana provides dynamic visualization options such as pie charts, line charts, tables, and geographical maps. It also enables you to search for specific events within the data and facilitates diagnostics and root-cause analysis. While the open-source version of Kibana lacks built-in alerting features, upgrading to Elastic X-Pack provides this functionality.
Prometheus and Grafana:
Prometheus is a powerful metric collection system capable of scraping metrics from Elasticsearch. When coupled with Grafana, a visualization tool, you can analyze and display Elasticsearch data over extended periods. Grafana offers flexible charts, heat maps, tables, and graphs, as well as built-in dashboards that can display data from multiple sources. Grafana's community also provides a large number of ready-made dashboards that can be imported and utilized.
Cerebro:
Cerebro is an open-source web admin tool specifically designed for Elasticsearch. It enables users to monitor and manipulate indexes and nodes while providing an overall view of cluster health. Cerebro is easy to set up and includes capabilities such as resyncing corrupted shards, configuring backups using snapshots, and activating indexes with a single click. However, it has a smaller community, resulting in less frequent updates and fewer features. Additionally, Cerebro does not support data from logs and lacks historical node statistics and anomaly detection capabilities.
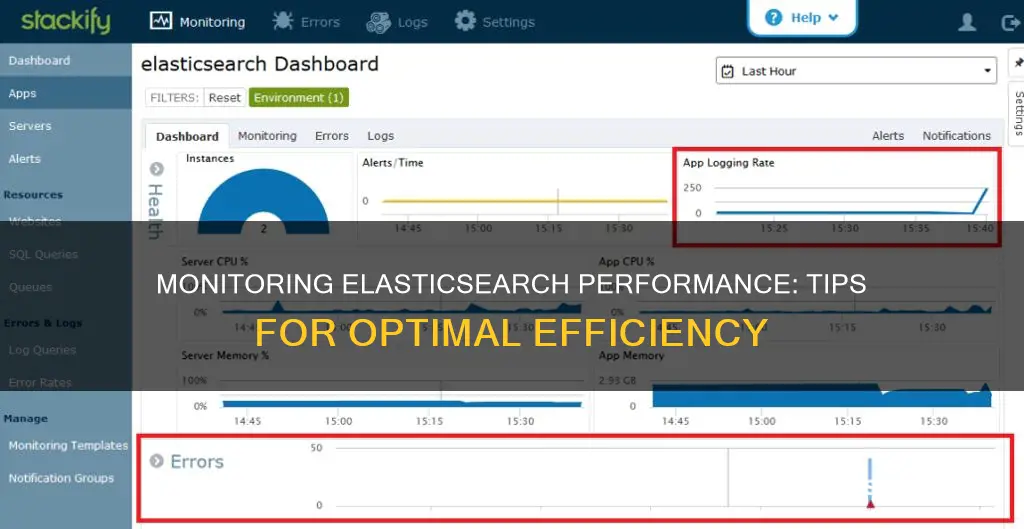
Stackify:
Stackify provides a range of application and server monitoring capabilities for Elasticsearch clusters. By installing the Stackify agent on all servers in your cluster, you can monitor core server metrics such as server availability, CPU, memory, disk space, and network adapters. Stackify also allows you to monitor the Elasticsearch service, including service status, CPU, and memory usage. Additionally, Stackify can monitor Elasticsearch's REST APIs, such as cluster health, cluster stats, and node stats, providing a comprehensive view of the Elasticsearch service's performance.
Ankle Monitors: Effective Surveillance or Easy to Cheat?
You may want to see also
![]()
Monitor network and thread pools
Monitoring network and thread pools is crucial for maintaining optimal performance in your Elasticsearch environment. Here are some detailed instructions and insights to help you effectively monitor these aspects:
Understanding Thread Pools
Each node in an Elasticsearch cluster utilises various thread pools to efficiently manage memory consumption and handle different types of requests. These thread pools are automatically configured based on the number of processors detected in each node. It's important to note that while you can modify thread pool settings, it's generally not recommended to tweak them unless necessary.
Important Thread Pools to Monitor
The following thread pools are crucial for the overall performance of your Elasticsearch cluster:
- Search: This thread pool handles search-related operations and is vital for query performance.
- Index: Responsible for indexing operations, including updating indices with new information. Monitoring this thread pool helps identify issues with data sources.
- Merge: Involved in the merging process of index segments, which can impact the performance of your cluster.
- Bulk: Handles bulk requests, such as single-document index/delete/update and bulk indexing operations.
Monitoring Thread Pools
You can monitor thread pools using the _
- GET /_cat/thread_pool\?v: This command provides details about each thread pool, including its current size.
- GET /_nodes/thread_pool: Retrieves information about the current size of each thread pool.
- GET /_nodes/hot_threads: Allows you to identify which threads are utilising the most CPU or taking the longest time, helping you locate potential performance bottlenecks.
Thread Pool Issues and Troubleshooting
Thread pool issues can arise due to a large number of pending requests, a single slow node, or thread pool rejections. Monitoring thread pool queues is crucial, as they have a direct impact on cluster performance. If queues become full, Elasticsearch nodes may struggle to keep up with the request speed, leading to rejections and potential node unresponsiveness.
To address thread pool issues, continuous monitoring is essential. Based on thread pool queue utilisation, you may need to review and control indexing/search requests or consider increasing the resources allocated to your cluster. However, increasing the queue size should be done cautiously, as it can lead to increased memory consumption and potential performance degradation.
Network Monitoring
In addition to thread pool monitoring, it's important to keep track of network-related metrics. Monitor disk I/O, CPU usage, memory usage, and node health for each Elasticsearch node. Pay close attention to Java Virtual Machine (JVM) metrics, especially when CPU spikes occur, as Elasticsearch operates within the JVM environment.
Blind Spot Monitor Standardization in Hyundai Santa Fe Models
You may want to see also
![]()
Collect and analyse logs
Collecting and analysing logs is a crucial aspect of monitoring Elasticsearch performance. Logs provide valuable insights into the health and performance of your Elasticsearch environment. Here are some detailed steps and best practices to effectively collect and analyse logs:
Collect Logs from All Sources
It is important to centralise your logs by collecting them from across your infrastructure. This can be achieved using a logging application such as Log Collector. By gathering logs from various IT resources, including network devices, servers, and applications, you can easily query and analyse them from a single location. This centralisation simplifies the process of monitoring and managing your IT resources.
Standardise and Index Logs
Once the logs are collected in a central location, it is essential to standardise them by organising them in a common format. This ensures uniformity and makes the logs more understandable. Additionally, indexing the logs is crucial to make the data easily searchable, facilitating efficient log analysis. Standardisation and indexing together enable faster troubleshooting and more effective monitoring.
Search, Analyse, and Visualise Logs
The collected logs can be searched and analysed by matching patterns, such as severity levels or exceptions. Kibana, an open-source data visualisation tool, is often used for this purpose. It integrates with Elasticsearch and allows users to explore log aggregations, create visual representations like graphs and charts, and derive insights. With Kibana, you can create dashboards and reports to share information with stakeholders, making it easier to spot trends and understand the data.
Set Up Alerts and Monitor Logs
Alerts can be configured to notify you when specific conditions are not met. This proactive monitoring helps in detecting issues that impact the performance of your IT resources. For example, you can set up alerts to monitor cluster health, node availability, index performance, and search performance metrics. By identifying anomalies and triggering alerts, you can take appropriate countermeasures to avoid risks and ensure the optimal performance of your Elasticsearch environment.
Best Practices and Recommendations
- Monitor high-level data: Collect and monitor high-level data across your entire system. This helps in identifying significant issues and provides a broader context for troubleshooting.
- Choose the right data sources: Think about the best place to get the data. Instead of adding more instrumentation, consider utilising existing APIs that can provide valuable information with less effort.
- Collect comprehensive data: Collect a variety of data before you know you need it. This proactive approach ensures that you have the necessary information when analysing logs and troubleshooting issues.
- Monitor thread pools: Keep an eye on thread pools like search, index, merge, and bulk. Issues in thread pools can be caused by pending requests, slow nodes, or thread pool rejections, leading to performance degradation.
- Manage memory consumption: As Elasticsearch indices grow, effectively monitor and manage memory consumption to avoid stability issues and data loss. High memory consumption can cause technical issues and impact performance.
- Consider alternatives to Elasticsearch as the primary log data store: Using Elasticsearch as the primary backing store for log data carries the risk of data loss in larger clusters with high daily volumes. Explore alternative storage options to prevent data loss and simplify data migrations.
Chevy Equinox: Blind Spot Monitoring Feature Explained
You may want to see also
Frequently asked questions
Some of the key metrics to monitor are cluster health and node availability, index performance, search performance, and network and thread pool monitoring.
By installing the Stackify agent on all servers in your Elasticsearch cluster, you can gain insight into core server metrics such as server availability, CPU, memory, disk space, and network adapters.
In Stackify's app dashboard, enable Elasticsearch service monitoring under Monitoring / Apps / System V Service / elasticsearch. This will give you a dashboard aggregating data for alerts, server CPU and memory, and Elasticsearch service CPU and memory for all instances.
Elasticsearch uses Apache's log4j library for all Java application logs. You can use Stackify to view or tail these log files, or send the logs directly to Stackify using their log4j appender.